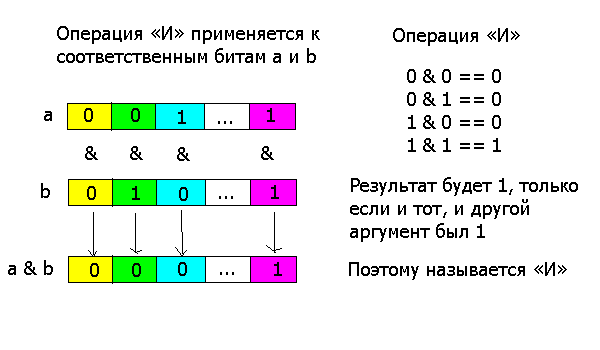
Документировать функции не обязательно. Но это хорошая идея в следующих сценариях:
За образец документации функции или класса можно взять любую систему документации успешных коммерческих продуктов. Например:- Вы публикуете свою библиотеку, чтобы ей пользовались разработчики других продуктов. Чтобы разработчики могли пользоваться вашей библиотекой, им нужно разъяснение, что ожидать от ваших функций и классов.
- Вы пишете проект в сотрудничестве с кем-то. Ключ успешного сотрудничества в хорошей коммуникации, и документация здесь первостепенна.
- Вы хотите написать поддерживаемый код. Вы когда-то перестанете работать в текущей фирме, и ваш продукт будут поддерживать другие люди. Чтобы ваш проект не умер одновременно с вашим уходом, следует позаботиться о нём заранее.
- Microsoft поддерживает документацию к средствам разработки приложений под Windows на высочайшем уровне. Для этого существует специальный сайт, MicroSoft Developer Network (MSDN). Пример документации функции: MessageBox.
- Oracle подробно документирует классы стандартной библиотеки языка Java. Из-за специфики языка функции сгруппированы по классам, часто описание функций одно- и двух-строчное. Пример: GroupLayout.setAutoCreateGaps.
- Сайт cplusplus.com описывает стандартную библиотеку языков C и C++. Пример: malloc.
- Google поддерживает документацию к всё новым версиям системы Android
- и т. п.
- Выжимка. В одно-два предложения излагает суть, что функция или класс делает.
- Синтаксис. Как вызывать функцию.
- Подробное описание. В случае, если выжимки недостаточно, приводится более развёрнутое объяснение.
- Параметры функции. Объясняется смысл каждого параметра, правила для него, ожидания и т. п.
- Значение возврата функции. Если функция что-то вычисляет, это надо объяснить.
- Какие ошибки могут происходить при работе функции
- Примеры кода, как использовать эту функцию или класс
- Дискуссия и комментарии пользователей